| ||
| ||
| ||
| ||
| ||
| ||
|
Linux Fast-STREAMS
Description: OpenSS7 Documentation Performance.
Recent Test Results
The test results shown below are for one of the initial beta package releases of Linux Fast-STREAMS: in particular the streams-0.7a.4 release. Performance of Linux Fast-STREAMS pipes is now almost an order of magnitude faster than these old results. Current results performed on the streams-0.9.2.3 and LiS-2.18.6 releases are detailed in the paper: STREAMS-based vs. Legacy Pipe Performance Comparison. This paper details that current results show Linux Fast-STREAMS about 5 times faster than legacy Linux pipes, and about 25 times faster than LiS pipes.
At one time we used to gauge the speed of Linux Fast-STREAMS and LiS with how fast they could pass data of various sizes (but particularly 64-byte read/writes) through a STREAMS-based pipe versus a Linux Legacy pipe. For the most part (as seen below), STREAMS-based pipes performed a lot (LiS) slower than Linux legacy pipes or a little (Linux Fast-STREAMS) slower. Pipe performance of 95% for Linux Fast-STREAMS was considered good. Currently, however, although LiS remains at about 25% to 40% of a Linux legacy pipe, Linux Fast-STREAMS has blown past Linux on the benchmark, performing at about 300% to 600% of a Linux legacy pipe. Below are two examples extracted from the report that show Linux having its clock cleaned.
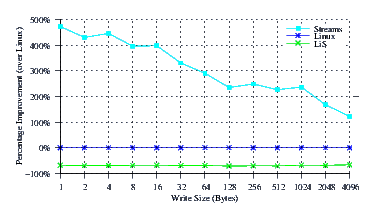
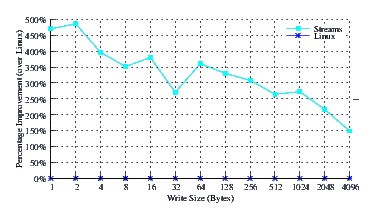
I do not think that there will be any further need for performance tuning of the Linux Fast-STREAMS Stream head for some time to come. Anyone on LKML wishing to complain about how slow STREAMS is had really better first get about fixing their legacy pipe implementation. And watch out, the Linux legacy BSD pseudo-tty implementation is the next target.
See also a demonstration of Linux Sockets having its clock cleaned by STREAMS on UDP and a demonstration of Linux Sockets TCP having its clock cleaned by STREAMS SCTP.
Old Test Results
The old test results are below for comparison purposes.
Test Configuration
Testing was performed on a 2.57 GHz UP Pentium IV machine with a 333 MHz FSB, and a 1.7 GHz UP Pentium IV notebook.
The following distributions and kernels were tested:
| Acronym | Distribution | Kernel | Machine |
|---|---|---|---|
| RH7.2 | RedHat Linux 7.2 | 2.4.20-28.7bigmem | 2.57 GHz UP 333MHz FSB |
| CL4 | CentOS Linux 4.0 | 2.6.9-5.0.3.EL | 2.57 GHz UP 333MHz FSB |
| FC4 | Fedora Core 4 | 2.6.14-1.1644_FC4 | 2.57 GHz UP 333MHz FSB |
| MDK | Mandriva LE 2005 | 2.6.11-12mdk-i686-up-4GB | 1.7 GHz UP Notebook |
| WBEL3 | WhiteBox Ent. Linux 3 | kernel | 2.57 GHz UP 333MHz FSB |
| SuSE9.2 | SuSE 9.2 | 2.6.8-24.13-default | 2.57 GHz UP 333MHz FSB |
The perftest program distributed with both the LiS-2.18.2-1 and streams-0.7a.4-1 packages was used to measure maximum throughput at various message sizes from 4 bytes to 4096 bytes in power of 2 increments. The perftest program simply performs writes of the given size to one pipe-end until it can no longer write and then reads from the other side, and so on.
Linear regression was performed on the results to determine the byte transfer throughput (slope) and write-read delay (intercept) for each pipe(2) implementation.
Linux Regression Transfer Throughput
The following chart depicts the Byte Transfer Througput for the results of the perftest program. The results, in Gigabytes per second, indicates the transfer ability of the pipe(2) to pass data from one pipe end to another. Although STREAMS preserves record boundaries and the Linux native pipes do not, Linux Fast-STREAMS performed well in comparison to Linux.

These results largely indicate the performance of memory allocation an deallocation and the speed of transfer of data to and from the pipe-end. Although the Linux native pipe(2) implementation allocates pages and does not preserve record boundaries, and the STREAMS implementations allocated buffers, Linux Fast-STREAMS use of buffer caches, single allocation of combined message and data blocks, and fast free lists, performed well in comparison to Linux native pipes.
Linux Regression Write-Read Delay
The following chart depicts the Write-Read Delay for the results of the perftest program. This is the non-byte correlated overhead associated with a write to one pipe(2) end and a read from the other.

Linux Fast-STREAMS performed well in comparison to Linux Native pipe(2) implementation and far exceeded the performance of LiS. LiS obviously has a inefficient Stream head implementation. Linux Fast-STREAMS even exceeds the performance of Linux native pipes on the Fedora Core 4 2.6.14 kernel.
Write-Reads at 64-bytes
The load point of most interest to the OpenSS7 Project is the 64-byte write-read load point. This is a STREAMS FASTBUF, and is the largest chunk of data used in transfering audio, video, or signalling information along a Stream. The following chart depicts the overall performance of each implementation on each kernel transfering 64-byte writes and reads.

At 64-byte write-reads, Linux Fast-STREAMS performs comparably to (and in the case of the FC4 2.6.14 kernel, exceeds the performance of) Linux native pipes. Linux Fast-STREAMS far exceeds the performance of LiS.
Performance Improvement over LiS
The following chart depicts the performance increase factor of Linux Fast-STREAMS and Linux native pipes over LiS compiled without optimization.

Linux Fast-STREAMS exhibits 5 to 12 times the peformance of LiS. Linux native pipes exhibit 5 to 16 times the performance of LiS.
Performance Improvement over LiS with Optimizations
The following chart depicts the performance increase factor of Linux Fast-STREAMS and Linux native pipes over LiS compile with optimizations.

Linux Fast-STREAMS still performs 3 to 6 times faster, while Linux native pipes perform 3 to 7 times faster than LiS.
Performance Improvement over Linux Native Pipes
The following chart depicts the performance factor for Linux Fast-STREAMS and LiS in comparison to Linux native pipes.

It can clearly by seen that LiS pipe implementation is unsuitable for replacement of Linux native pipes, whereas, Linux Fast-STREAMS exhibits comparable or superior performance to Linux native pipes. As STREAMS-based pipes are far more feature-rich than SVR 3 style Linux native pipes, while retaining POSIX compliance, much would be gained by replacing the antiquated SVR 3 style Linux native pipes with Linux Fast-STREAMS STREAMS-based pipes.
(Any one complaining on lkml about the dismal performance of STREAMS had better fix their pipe implementation!)
Copyright © 2014 OpenSS7 Corporation All Rights Reserved.